VoxAct‐B: Voxel‐Based Acting and Stabilizing Policy for Bimanual Manipulation
Type
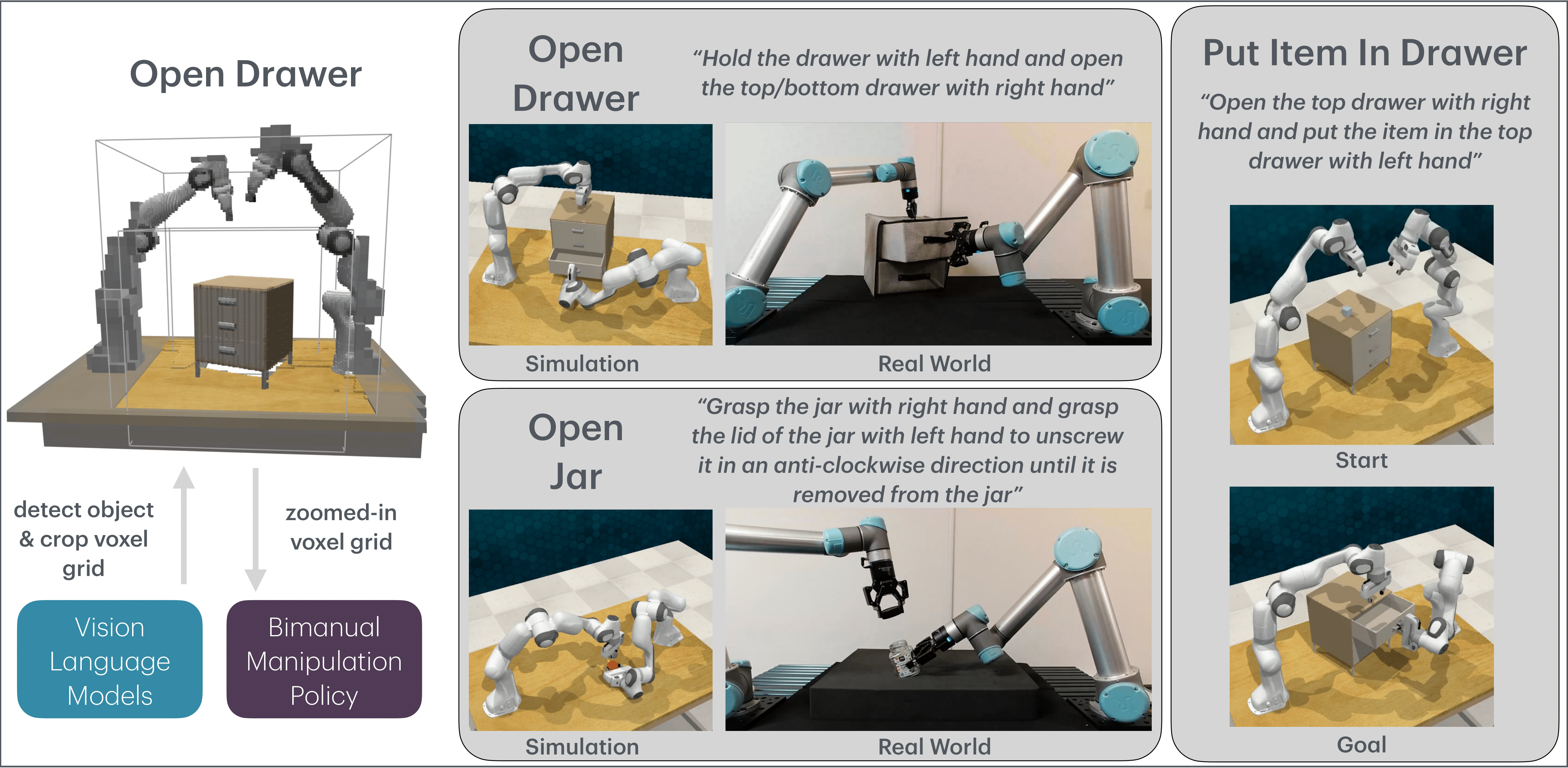
Abstract
Bimanual manipulation is critical to many robotics applications. In contrast to single-arm manipulation, bimanual manipulation tasks are challenging due to higher-dimensional action spaces. Prior works leverage large amounts of data and primitive actions to address this problem, but may suffer from sample inefficiency and limited generalization across various tasks. To this end, we propose VoxAct-B, a language-conditioned, voxel-based method that leverages Vision Language Models (VLMs) to prioritize key regions within the scene and reconstruct a voxel grid. We provide this voxel grid to our bimanual manipulation policy to learn acting and stabilizing actions. This approach enables more efficient policy learning from voxels and is generalizable to different tasks. In simulation, we show that VoxAct-B outperforms strong baselines on fine-grained bimanual manipulation tasks. Furthermore, we demonstrate VoxAct-B on real-world Open Drawer and Open Jar tasks using two UR5s. Code, data, and videos are available at https://voxact-b.github.io.Accepted to Conference on Robot Learning (CoRL), 2024.
Authors: I-Chun Arthur Liu, Sicheng He, Daniel Seita*, Gaurav S. Sukhatme*.
* denotes equal advising.
Blog post: https://rasc.usc.edu/blog/voxact-b/.
Twitter thread: https://x.com/arthur801031/status/1851072842114482222.
I-Chun (Arthur) Liu
CS (Robotics & AI) PhD Candidate
My research interests are in imitation learning, deep reinforcement learning, and vision for bimanual robotic manipulation.